|
|
SAS Text MinerSAS文本挖掘可以做什么?SAS Text Miner结合了Teragram所提供的先进语言学技术,将其整合到SAS Enterprise Miner的核心数据挖掘解决方案之中。这是一套全面的文本挖掘解决方案,可以帮助您将非结构化数据(自由形式文本)和结构化数据整合在一起,从而在集成的预测建模环境中,为企业提供完整的视图和有价值的分析结果。自动化理解文本数据源(而不需要手动分析),结合交互式的深入钻取报告,同时利用严谨先进的数学分析算法,让您可疑抓住未来趋势,在面对新时机时及时有效地采取行动,同时降低风险。  SAS文本挖掘为什么重要?SAS Miner可以自动化阅读和解析文本这些原本非常耗时的任务,节约成本和资源。同时,通过整合结构化数据和非结构化的文本信息,你就可以获得更加精准的企业视图。可以对这两种类型的数据展开分析,生成描述性模型和预测性模型,发现更多的业务机会,更准确地识别出趋势,从而能够制定出更好的决策来指导行动。 SAS文本挖掘为谁而设计?SAS Text Miner主要面向必须查看大量的文本来提取信息、获得创意和了解趋势的业务分析师和统计人员。该软件可应用在所有的行业和政府部门,而对于积极营建预测模型的企业用户来说尤其重要 企业每天都会产生大量文本形式的信息。包括用户回馈、e-mail、Web文档、博客、微博、备忘录、保修索赔、调查问卷、期刊文章、调查研究、简历、客户记录、竞争分析等等…而且这一清单还在不断增长。没有人会有足够的时间来阅读所有的文档,更不用说对这些文本信息进行组织和分类,也就很难充分利用这些信息。 要想从这些已收集的数据中获取最大化的价值,就需要对它们进行有效地分析。但是由于会话语言的模糊性和多样性,导致很难识别、量化、分析或利用隐藏在文本数据中的信息。而且,大多数企业在决策过程中都缺乏整合文本信息与结构化数据的能力。 借助SAS Text Miner,您可以将文档分类到预先定义的或由数据驱动的类别中,找出主题之间隐含的关系或关联,整合文本数据和结构化数据。交互式探索能够帮您发现文档集合中那些以前未知的模式,然后将这些知识用在预测性模型中,从而发掘出所有信息源的最大价值。 一、主要优点(1)通过自动化处理,缩短决策时间。 (2)揭示以前未知的关联关系,加强发现处理能力。 (3)直观显示高层次的数据视图,深入挖掘文档中的特定词组。 以一整套预测模型工具帮助您识别趋势和把握商机。对消费者来信和呼叫中心记录的信息分析,能够提供有关用户不满或服务及产品需求等方面的重要信息。 二、产品概述 SAS文本挖掘软件提供了丰富的语言学和分析建模工具,用来从繁多的文本文档中发现提炼有用的信息并进行预测。文本经过转换后会变成结构化数据,可以提供给后续的数据挖掘引擎进行挖掘。主题和话题也被识别出来,形成明确的关联关系,这样就可以对文档进行聚类,划分到相关的群组中,用于后续的评分或者预测型模型。提供高性能的搜索功能,增强型的拼写检查和处理单文档中包含多个话题的能力。SAS Enterprise Content Categorization(SAS企业内容分类)的分析结果,或者是SAS文本挖掘软件中的概念创建插件产生的分析结果,都可以直接整合在您的文本挖掘系统中,用以补充您创建的自定义实体。 (1)访问多种格式和语言的文档 SAS Text Miner可以读取以各种文档格式存储的文本。它还可以进行预处理,将多种格式的文档转换成SAS数据集,以便输入到SAS文本挖掘系统中。 这使您可以在单个系统中整合多种数据源(包括通过网页抓取功能获得的互联网和社会媒体网络信息),进行信息分析。它还包括自定义的程序和阿拉伯语、中文、英语、法语、德语、意大利语、葡萄牙语、日语、韩语、波兰语、瑞典语、荷兰语和西班牙语等字典。它还能对所支持的语言进行实体抽取。对于那些目前尚不支持的语言,您可以使用Unicode UTF-8编码来进行处理。 (2)友好灵活的用户界面 Java客户端/SAS服务器架构,提供了信息摘要图形,使您可以更轻松地进行文本文档挖掘,获得深入的洞察。通过服务器分层,可以将计算过程和用户界面分离开来。用户们在自己的桌面上操作时,强大的UNIX和Windows服务器可以处理密集型挖掘任务。这一功能提供了前所未有的灵活性,方便您从单用户平台扩展到企业级解决方案。此外,当模型创建后,界面可自动生成评分代码。评分代码可以导出和部署到常用的商业智能客户端软件中,包括Microsoft Excel、SAS Enterprise Content Categorization、SAS Enterprise Guide和JMP。 全面的文本解析于分解文本数据,通过量化的表达方式,用于后续的数据挖掘。SAS Text Miner增加了新的文本解析节点,将文本数据解析成为有意义的词性、地址、电话号码以及公司名称,包括词干或词根。这种增强型的解析器,让您可以选择忽略一些停用词或者指定同义词。在原有的解析功能上,又新增了多词短语和用户自定义实体等功能。 (3)降维  (4)文本主题识别和聚类 通过先进的算法,可以根据文本内容将文档自动分组成多个常见话题和主题。与以往将文档硬性划分到某个单一主题(也称'硬聚类')不同,SAS Text Miner 4.2提供了新的文本主题节点,任何给定文档都可以和多个兴趣主题相关联,或者是不和任何主题关联。这些主题可以由用户定义,或者由工具自动判别。文本主题节点的交互式界面,让用户能够查看文档聚类以及与之相关联的不同主题,并随时调整主题定义。当然,如果您需要硬聚类,可以使用文本挖掘节点,将主题对应到聚类层次或聚类列表上。期望最大化聚类,应用了空间聚类技术来组织文档分组。您还可以在原始文本文档旁边,以一种易于解释的方式显示聚类摘要。交互式可视化环境,使分析人员能够探索文档间的概念和关系,并进行动态修改,以便后续的处理和分析。 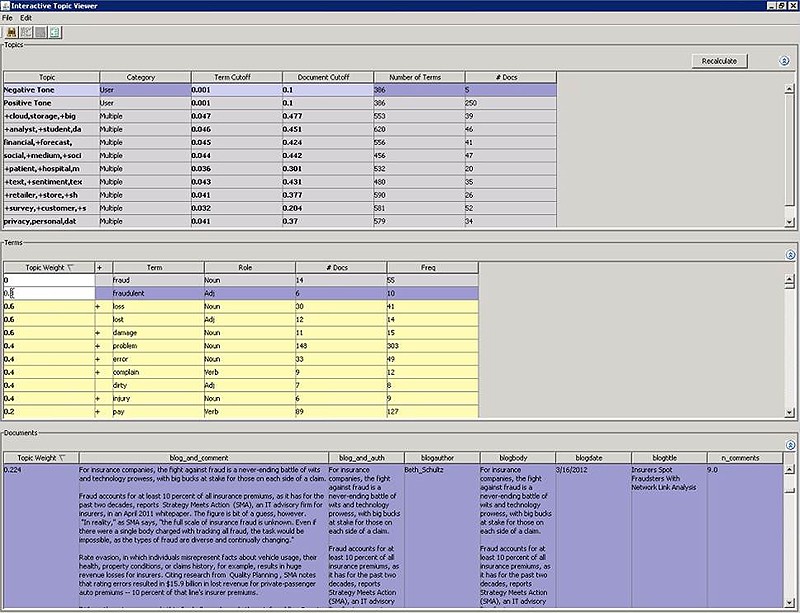 (5)文本过滤 SAS Text Miner包含文本过滤节点,提供了集成的全文搜索、自动拼写检查,概念链接、以及对词条和文档抽取子集等功能。交互式查询,可以让您按照自己指定的搜索参数检索各个匹配文档。过滤器可以基于任何特征进行过滤,包括是否包含某些词条等。而且交互式可视化使您能够进行深入探查,直到您找到所需的文档和词条。在概念图中将词条、短语和实体以可视化的方式链接起来,并提供交互式的操作,让您可以识别以前未曾检测出的模式。 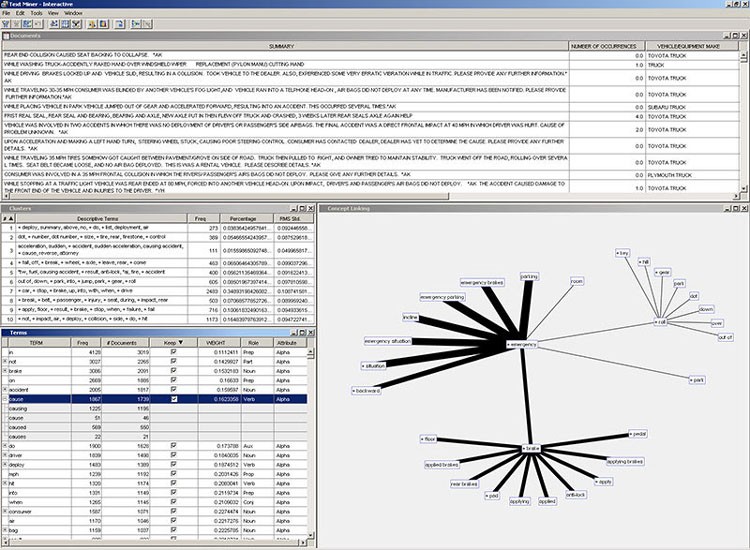 (6)直接应用其它SAS分析软件的分析结果 SAS Text Miner可以与SAS的主流预测建模软件或其它新的SAS文本分析产品无缝集成,提供一整套的文本和结构化数据的挖掘工具,以及数据处理、评分和部署工具。采用SAS获得高度好评的分析软件,企业能够在他们的运营环境中部署分析系统,有效地解决关键的商业问题。 三、主要特点 (1)通用数据访问
(2)支持多种语言
(3)友好灵活的用户界面
(4)文本解析节点
 (5)降维技术
(6)文本主题节点
(7)文本聚类算法

相关文档
在线留言尊敬的客户朋友,如您有任何意见建议,请通过下表反馈给我们,我们会尽快与您联系。
|
|
|
||||||||||||||||||||||||


