XLSTAT 2025.1版本最新更新
更智能的洞察。更快的工作流程。由 AI 提供支持。
向 XLSTAT 的下一次发展问好。凭借 AI 驱动的统计洞察、现代化的用户界面和新的定制软件包,XLSTAT 2025.1 可帮助您以前所未有的速度从数据到决策。无论您是在探索趋势还是处理复杂的模型,新的 AI Assistant 都能让您简单、快速、准确地解释您的结果--无需编码,完全在 Microsoft Excel 中。
XLSTAT 2025.1 中有哪些新增功能
内置 AI 助手
在 XLSTAT Advanced 中可用
获取即时见解 - 无需编码。新的 XLSTAT AI Assistant 可以汇总数据集、解释结果,并通过智能建议指导您进行分析,从而使各种技能水平的用户都能更轻松地进行统计。
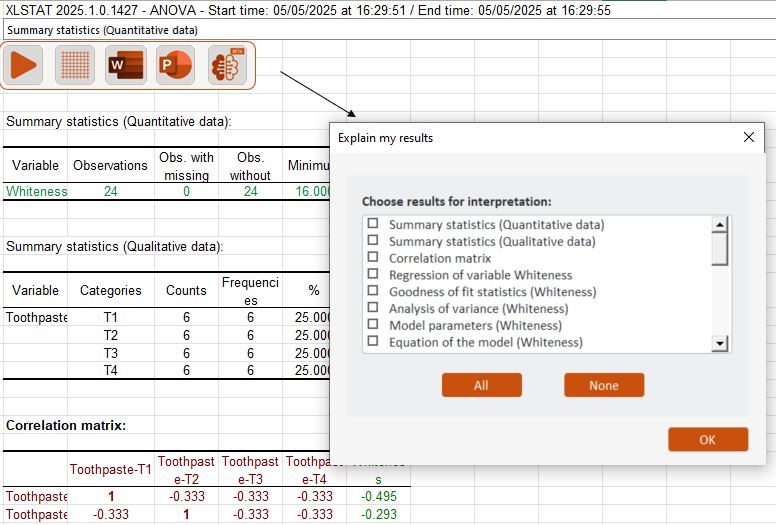
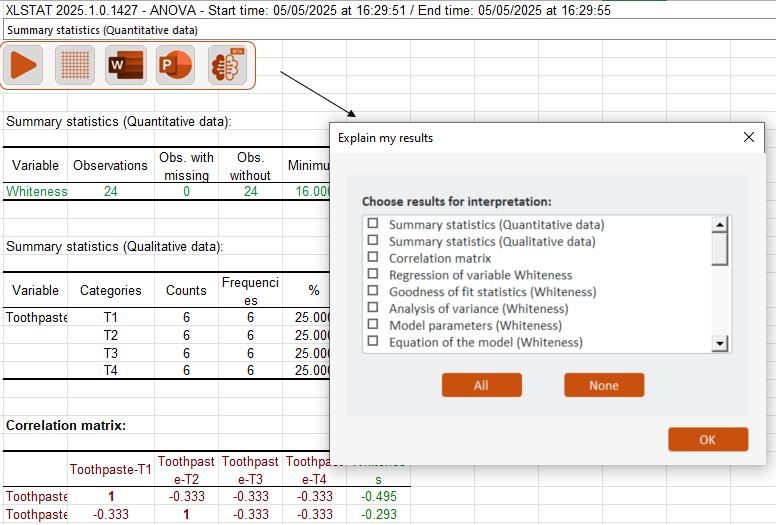
重新设计的简化界面
所有 XLSTAT 版本中均可用
以更少的点击次数执行复杂的分析。更新后的设计为您的工作流程带来了更大的清晰度和控制力,并将直观的用户体验直接内置到 Excel 中。
用于多重比较的 Holm-Bonferroni 校正
所有 XLSTAT 版本中均可用
确保您的统计分析既精确又可靠,因为 XLSTAT 现在支持用于多重比较的 Holm-Bonferroni 校正。此校正在方差分析中可用,并扩展到其他检验,包括 Mann-Whitney、Kruskal-Wallis(使用 Dunn 事后检验)和 Friedman(使用 Nemenyi 事后检验),为您提供更强大的假设检验工具。
增强的倾向得分匹配
在 XLSTAT Advanced 中可用
更灵活地分析治疗效果。XLSTAT 2025.1 引入了一项强大的新功能,用于随意推理。更新的倾向得分匹配工具现在允许您通过输出选项卡中的新选项从匹配的观察值(处理组和对照组)中提取原始数据。
三种量身定制的套餐
查找满足您组织特定分析需求的完美 XLSTAT 套装。为了满足对平衡简单性和复杂性的工具日益增长的需求,XLSTAT 2025.1 引入了三个新设计的选项:
- Essential:用于快速高效数据探索的基本工具。
- Standard:全面的感官和消费者洞察功能。
- Advanced:用于预测建模、自动化工作流程、AI 驱动的洞察等的复杂功能。
XLSTAT 旨在支持从消费者行为和临床试验到财务建模和产品开发的行业,作为嵌入在 Excel 中的最通用的统计解决方案脱颖而出,由 Lumivero 专门从事感官和消费者数据的专家团队提供支持。
在线留言
尊敬的客户朋友,如您有任何意见建议,请通过下表反馈给我们,我们会尽快与您联系。
|



{kind=link}
{kind=link}