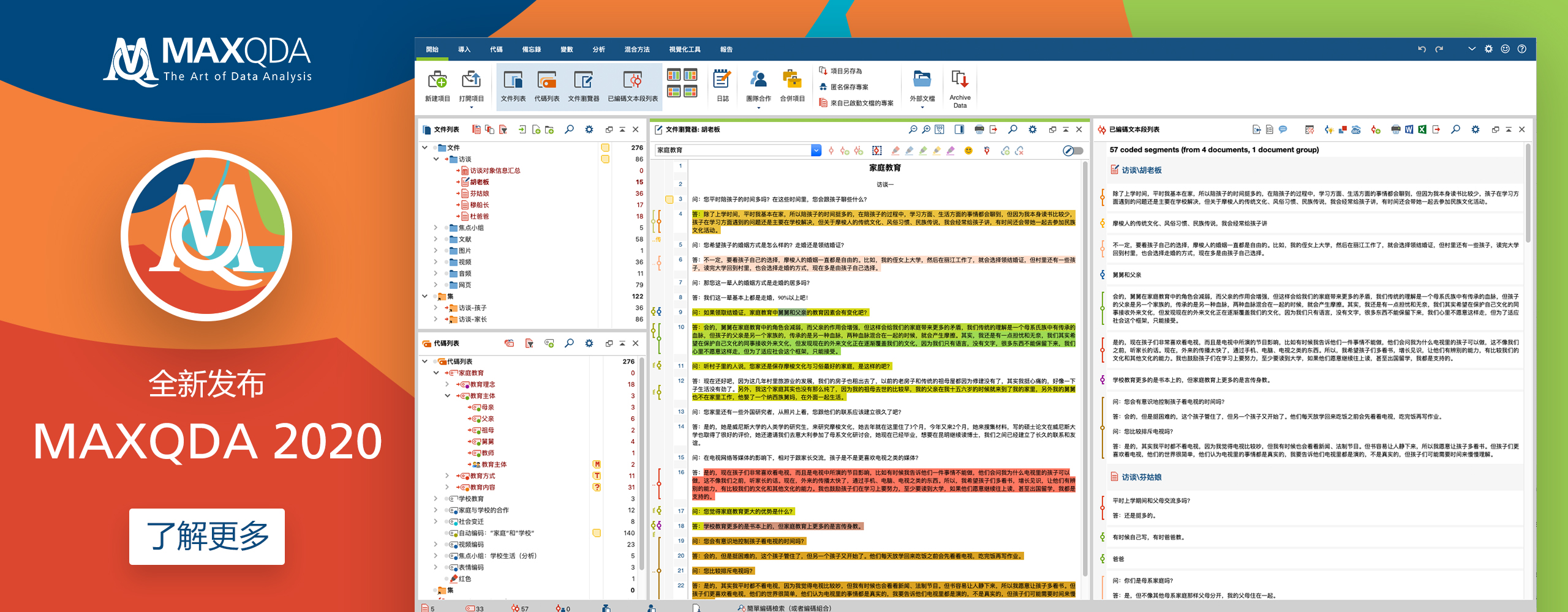
MAXQDA 2020版最新更新
MAXQDA 2020.4更新(2021年3月3日)
[新增]
推特数据的情感分析
- 使用AI词汇方法分析推文以发现其情感。
- 推文会自动按照从正到负的等级进行分类。
- 使用情感评分自动对推文进行编码。
- 根据情感得分对推文进行过滤和排序。
- 在图表中显示情绪分析的结果。
新的示例项目
- MAXQDA中增加了一个有关“工作与生活平衡”的新英语示例项目。 该项目包含各种类型的数据,您可以使用它们来测试或教授MAXQDA。
[改善]
VISUAL TOOLS & DIAGRAMS
- Document Map: Save the documents in a cluster as a Document Set, either for a specific cluster or for all clusters at once.
- Activate or deactivate "Link" mode in MAXMaps with the new keyboard shortcut CTRL+L (Win) or cmd+L (Mac).
- Improved column width in Visual Tools while using a Mac while the MAXQDA font size setting is "large".
- New scatter plot options in MAXQDA Stats: Scale axis equally, and edit the diagram title, color schemes, or labels.
IMPORT & EXPORT
- Improved handling of data imported from .DOCX documents: Improved font recognition, image sizes, line spacing, and support for special .xml files.
- Improved import of transcripts created with the latest version of the automatic transcription services Otter.ai, TEMI, and REV.
- A native import for SPSS data was implemented to replace a previously used third-party-component that is currently not notarized by Apple. You can now again import, create, or export SPSS files (.sav) on a Mac.
- Export all of the statistic tables currently included in a statistics window to Excel at once. Each table is saved to a separate Excel worksheet tab.
GENERAL
- Hover over a variable in the Activate by Variable window to view the full name of the variable as a tooltip.
- Improved workflow in the Summary Grid. Click on a node in the grid to make the cursor jump to the summary window and start typing right away.
- New sorting option for memos in the Memo Manager. You can now sort memos by title.
- Search within your tweets to find tweets that contain a specific word. Create tweet statistics and word clouds for only those tweets containing the search word.
- Several interface design improvements for both light mode and dark mode.
- The Overview of Coded Segments table is now initially sorted by the Document System.
[修正]
- Fixes an issue while adjusting a text selection in a PDF document where selections across two pages were not adjusted correctly.
- Fixes an issue while analyzing Word Frequencies, where the option to differentiate results by codes may have been disabled.
- Fixes an issue while assigning internal links where assigning multiple links to the same segment was possible.
- Fixes an issue while changing the content of a memo in the Memo Manager where the changes were not applied to the Overview of Memos until the Memo Manager was closed.
- Fixes an issue while closing the Reliability Analysis dialog in Stats, where in specific cases the software stopped working.
- Fixes an issue while displaying unnecessary paraphrased segments in the "Overview of Coded Segments"
- Fixes an issue while duplicating a document where the code frequency in the Code System was not immediately updated.
- Fixes an issue while duplicating documents in the Document System where brackets behind the documents name were dropped.
- Fixes an issue while editing an in-text-memo at the same time as the text in the document itself where the memo edits were not saved correctly.
- Fixes an issue while exporting .sps files where the files were not correctly recognized in SPSS.
- Fixes an issue while exporting an Interactive Quote Matrix to Excel, where the document names in the source information were not included.
- Fixes an issue while importing RIS data where PDF files were not embedded in the project file.
- Fixes an issue while loading the MAXQDA style sheet on some Mac computers.
- Fixes an issue while recognizing "Modified" and "Modified by" variables while exporting and re-importing variables to and from Excel for project files with RIS literature data.
- Fixes an issue while renaming variables where it was possible to assign the same name to multiple variables.
- Fixes an issue while transforming a PDF document into a text document where the new text was not opened immediately.
- Fixes an issue while using "Fit to window" scaling in MAXMaps on screens with high resolution.
MAXQDA 2020 –开启研究创新的新纪元
对于即将开始2020年,我们问了自己一个简单的问题:是什么使全世界的研究人员都选择MAXQDA作为他们的第一研究软件,以及我们如何才能使这些出色的数据分析工具变得更好?经过30多年的创新,您将在MAXQDA 2020中找到我们对这个问题的答案。它以现有优势为基础,还提供了其他任何地方都无法找到的革命性新功能。我们来看一下!
MAXQDA 2020 – 功能亮点
备忘录的新焦点
强大的新功能使您比以往更轻松,更高效地访问,显示,创建和编辑备忘录
We know how important memos are to keeping track of ideas, thoughts and insights regarding your research. Memos can play a vital role in the analytical process and can often be the starting point for writing up report chapters. MAXQDA 2020 offers multiple new tools to work with memos more easily & efficiently.
- New memo sidebar. Display and read your memos alongside your data by displaying them directly next to your source material in the sidebar.
- New memo tab in the main menu. Access existing memos, write new memos or search for memos – all in one place!
- New Memo Editor. The newly designed Memo Editor expands your writing space – and you can now add tables to your memo texts.
- Memo links. Link parts of a memo to any section in the data to quickly jump back and forth – or link a memo to any number of codes and/or coded segments.
备忘录管理器
一个新的备忘录工作区,用于搜索,过滤和创建备忘录
These new Memo Manager features turns your memos into a complete project knowledge base.
- Filter and search. Filter and sort memos by type, date, author, or symbol. Search within all or only selected memos and quickly find memos attached to any element of your research.
- Work. Open several memos in tabs, combine a group of memos in a set, and use the new workspace to organize, compare and write up your notes.
MAXMaps 3.0
适用于思维导图工具的六个新模型和增强的交互性
通过MAXQDA 2020,我们在开发业内最先进的面向研究的可视化工具的道路上继续取得了新的突破。
With MAXQDA 2020, we have continued to make new breakthroughs on the road to developing the most sophisticated research-oriented visualization tools in the industry. MAXMaps now comes with six new models, new options for existing models, and a user-friendly interactive concept model builder.
- New interactive model builder. Interactively test any of the existing options for a model before creating a new map and save time creating the perfect map to illustrate your data.
- Six new models. The new models can visualize your project’s code by document distribution, related & overlapping codes, or put a spotlight on summaries and paraphrases.
- Map Organizer. The redesigned Map Organizer window now lets you add comments to a map, reorganize maps more efficiently and group maps into folders.
- New objects & formatting options. More flexibility to work with lines and arrows, better descriptions to illustrate relationships between elements, and a general design update for all formatting options that looks and works in a similar way to widely used office software packages.
检索片段窗口
经过重新设计,以适合您查看和使用编码段的方式。 新的显示选项将更多信息添加到数据显示
- Sidebar for comments. Display comments for a coded segment in a new sidebar next to your retrieved segments.
- Include variables. Display your favorite document variables and variable values.
- Coding stripes. Coding stripes are displayed next to retrieved segments to make it easier to find segments by code color.
- Subheadings. Coded segments are separated by subheadings: document names (when sorted by documents), code names (when sorted by codes), and weight scores (when sorted by weight).
- Hide source information. Hide coded segment source information to fully concentrate on the segments themselves.
文献评论
您现在可以导入完整的文章以及您的书目数据。
You can already import bibliographical metadata from Endnote, Mendeley, and Zotero into MAXQDA. In MAXQDA 2020, these import options additionally include the respective texts or PDF articles.
What’s more, MAXQDA also automatically recognizes duplicates, and attachments can be automatically coded during import with the keywords assigned to them.
从新来源导入转录
您的灵活性是我们的使命:从大量流行的转录服务和工具中导入转录本
New automatic transcription services for audio and video files are popping up every day – they are so much faster than manual transcription, and their automatic speech recognition is getting better and better. MAXQDA 2020 allows you to work with the automatic transcription service of your choice – and import transcripts and timestamps from commonly used online and offline applications.
Transcript sources include AmberScript, TEMI, Trint, f4, f5transkript, Transana, Rev.com, and more.
新的代码系统功能
使用新的拖放合并和一键式子代码功能,可以节省构建和优化代码的时间。 通过新的频率显示设置,您可以对数据中的代码分布获得新的见解。
- One-click subcode. Building up a code system has never been easier. Just hover over a code to see the one-click subcode feature, which you can use to create a new code on the spot.
- Drag & drop merge. Drag one code onto another code and simply drop it onto the new Merge area to combine two codes into one.
- Code frequency settings. Use this feature to adjust the frequency numbers displayed in the Code System. Choose to only count codes in selected documents or to count in how many documents, document groups, or document sets a code was applied in.
文本中的行和段落编号
在行或段落编号之间来回切换,并按所需方式引用源。
Quote and review interview transcripts and literature, now with the new line numbering text display. But don’t worry – paragraph numbers haven’t disappeared, and you can switch back to the original paragraph numbering system with one click.
And you can still customize your line numbering: set the maximum number of characters per line the way that works best for you.
新的编码功能
有两种方法可以使创建新代码和构建类别系统变得更加容易-非常适合扎根的理论
The new Open Coding Mode is perfect for researchers using the grounded theory approach. When activated, you can simply select a segment in a text, PDF or image and the dialog box for creating new codes will appear automatically.
In addition to adding a Code memo to the segment, the Open Coding Mode code windows also lets you attach a comment to the segment quickly and easily.
比较摘要
您是否用自己的话语总结了大量编码段? 现在,跨案例查看和比较这些压缩信息变得更加容易。
The new interactive Summary Explorer lets you compare all of the summaries associated with a code within a given document, document group, or document set – and quickly jump back to the original source.
The table of results doesn’t list all of the coded segments on a topic for each group, which can sometimes be difficult to keep track of; instead, it lists the condensed information on this topic in the form of summaries – written by you or your team of researchers.
文档图
获取图片:以可视方式对案例进行聚类以分析差异和相似性。 两种情况越相似,它们在地图上的距离就越近。
Display selected documents as if they were on a map to visualize the differences and similarities between documents: the greater the similarity between two documents – in terms of (selected) code assignments and (optionally) demographic data – the closer they are displayed to each other.
The map can then be exported as an image or saved as a map in MAXMaps. This is an ideal tool for clustering cases and for in-depth explorations of identified groups.
新释义功能
布置合理的工作区,可按案例或组查看所有释义。 现在您还可以解释图像片段。
- Paraphrase Matrix. Each column contains the paraphrases for a document, document group, or document set.
- Paraphrase images. Paraphrase different segments of an image.
- Printing paraphrases. Print a document (or think about our planet’s future and save it to PDF) with the complete paraphrases visible in the page margin.
数据归档
我们通过新的自定义归档选项完全致力于您数据的可持续性
In recent years, the topic of research data archiving has attracted increasing attention. The EU Commission on Competition adopted a resolution in 2016, requiring all publicly funded scientific publications in the EU to be freely accessible by 2020. This decision explicitly referred to the research data on which the publications are based.
In MAXQDA 2020, you can easily archive your data with a new single-click function. A clear and simple to understand folder and file structure is then generated that contains all your collected data – optionally also as a compressed ZIP file.
In addition to the original data sources, archives can also include statistical data, media data, memos, and your code system.
其他新功能和增强功能
General
 Interface: Access to local settings in all four main windows. The global settings have been reduced accordingly and are therefore much clearer. Interface: Access to local settings in all four main windows. The global settings have been reduced accordingly and are therefore much clearer.
Interface: The “Retrieved Segments” window is deactivated by default when starting a new project to allow more space for initial project tasks like reading, annotating, and coding.
Source Info: New option allowing you to automatically add the source information (document and location) to any text selection copied from the “Document Browser”.
 Export: Texts are no longer exported in RTF format, but in the Word format DOCX. Export: Texts are no longer exported in RTF format, but in the Word format DOCX.
 Paraphrases: Paraphrases in the “Categorize Paraphrases” window can be manually sorted to arrange similar paraphrases below one another. Paraphrases: Paraphrases in the “Categorize Paraphrases” window can be manually sorted to arrange similar paraphrases below one another.
 Activation: Randomly activate a user-defined number of documents. Activation: Randomly activate a user-defined number of documents.
Activation: While using the Activate by Document Variables feature, you can create new sets of documents that meet the conditions currently displayed without activating them at the same time.
Activation: The icon “Activate by…” icon in the Document System toolbar displays a menu with all available options for activating documents (by variables, by color, by random).
Documents
 Documents: Document tooltips now also include information about the last editing date and the last user who edited a document. Documents: Document tooltips now also include information about the last editing date and the last user who edited a document.
 Documents: New setting option allowing you to always open documents in new tabs. Documents: New setting option allowing you to always open documents in new tabs.
Documents: New setting option allowing you to insert new documents at the bottom instead of the top of the folder structure.
Documents: New setting option allowing you to determine which variables are displayed in the tooltip box that appears when hovering over a document.
Documents: Documents within document groups can be sorted by the date of last edit and the text length.
 Documents: New Edit Mode toggle switch to clearly visualize if a displayed document is currently in Edit Mode. Documents: New Edit Mode toggle switch to clearly visualize if a displayed document is currently in Edit Mode.
Documents: While working with text in Edit Mode, you can copy and paste texts along with their formatting.
Memos
 Memos: Add a memo to a code set. Memos: Add a memo to a code set.
Memos: New memo type “in-media memo” for all memos attached to a video or audio file.
Memos: New option allowing you to link a memo to one or several coded segments.
Memos: Changing the name of a document or memo automatically changes the name of the document memo or code memo (if the memo name was still the same as the document or code name).
MAXMaps
 MAXMaps: Create an automatic concept map directly from the document or code context menu (e.g. a Single Case Model for an interview). MAXMaps: Create an automatic concept map directly from the document or code context menu (e.g. a Single Case Model for an interview).
MAXMaps: Copy elements from one map to another via drag & drop.
MAXMaps: Add a new image to a map with a simple drag & drop of an image file from your computer.
MAXMaps: Connection lines between elements can now be curved.
MAXMaps: New option to hide or display Coded Segment symbols.
MAXMaps: New icon “Add to Library” in the Format tab and new icon “Insert from Library” in the Insert tab.
MAXMaps: When importing subcodes for a code, you can specify up to which level subcodes are to be imported.
MAXMaps: Imported subcodes, coded segments, summaries etc. can be limited to activated documents.
MAXMaps: Right-click on a memo to import linked codes or linked coded segments into the map.
MAXMaps: The Single-Case Model can now contain up to 20 coded segments.
MAXMaps: When creating a map from a model, each group of elements (e.g. documents, codes, memos, coded segments) are automatically added to a different layer
Codes
 Codes: In the options menu for the displayed coding stripes, you can restrict the color highlighting of coded text passages to currently activated codes. Codes: In the options menu for the displayed coding stripes, you can restrict the color highlighting of coded text passages to currently activated codes.
 Codes: Several simultaneously selected codes can be merged via the context menu. Codes: Several simultaneously selected codes can be merged via the context menu.
Codes: When merging codes, you can transform otherwise deleted code memos into free memos.
Codes: New option to activate all documents containing this code in a code’s context menu.
Codes: New context menu options to add code to an existing or new code-set.
Codes: New context menu options to add code to code favorites.
Codes: The displayed total of coded segments in the “Code System” and the “Document System” ignores paraphrased segments and focus group speaker codes.
Codes: Duplicate a code with its coded segment via the context menu.
 Smart Coding Tool: New search tool allowing you to search within the displayed section of the “Code System”. Smart Coding Tool: New search tool allowing you to search within the displayed section of the “Code System”.
Search
 Search: When searching for documents in the “Document System” or Codes in the “Code System” window, all found documents or codes can be activated immediately. Search: When searching for documents in the “Document System” or Codes in the “Code System” window, all found documents or codes can be activated immediately.
Lexical search: Search hits in the results table are highlighted in color.
Lexical search: The preview feature in the search results table displays multiple rows.
Lexical search: Search results can be saved as a variable with the variable value indicating how often the search strings occurs in a document.
Lexical search: When autocoding search results with a new code, a code name with the search words and a memo with the search settings are automatically suggested to you.
Mixed Methods
 Variables: Functions for focus group variables are available in the Variables tab Variables: Functions for focus group variables are available in the Variables tab
Variables: In the Data Editor, right-click a column header to create a frequency analysis for the clicked variable.
Variables: Two new system variables: “Modified on” and “Modified by”.
 Crosstab: Cells are now interactive: right-click on a cell to activate the corresponding documents. Crosstab: Cells are now interactive: right-click on a cell to activate the corresponding documents.
Crosstab for Focus groups: Limit a crosstab for focus groups to activated documents.
Crosstab for Focus groups: Right-click on a cell in the crosstab matrix to activate all focus group contributions in which the counted code assignments were made.
Visual Tools
 Code Matrix Browser: Clicking on a cell in the Code Matrix Browser lists the corresponding segments in the “Retrieved Segments” window without changing current activation patterns. Code Matrix Browser: Clicking on a cell in the Code Matrix Browser lists the corresponding segments in the “Retrieved Segments” window without changing current activation patterns.
 Code Relations Browser: New option to visualize “Occurrence of codes in the same document”. Code Relations Browser: New option to visualize “Occurrence of codes in the same document”.
Code Relations Browser: Right-click on a node in the matrix to activate all documents in which the displayed code relations occur.
Code Relations Browser: Active settings (collapsed codes, counting hits per document only once, binarization, filtering segments by selecting codes in the options dialog) are applied when creating a Code Map directly from this tool.
 Code Map: New option to display a grid on the map for easier comparison of distances. Code Map: New option to display a grid on the map for easier comparison of distances.
MAXMaps: New Models
 Single-Case Model (Summaries) places the case (document) at the center. The case is surrounded by all codes that have at least one summary, linked with lines. The corresponding summary texts are displayed for each code, also linked with lines. Single-Case Model (Summaries) places the case (document) at the center. The case is surrounded by all codes that have at least one summary, linked with lines. The corresponding summary texts are displayed for each code, also linked with lines.
Single-Case Model (Paraphrases) places the case (document) at the center. The case is surrounded by the paraphrase, linked with lines.
Single-Code Model (Summaries) places the code at the center. The code is surrounded by all of its summaries, linked with lines.
Code Co-occurrence Model (Code Proximity) works like the earlier Code Co-occurrence Model, except that the proximity of two codes in each of the selected documents is analyzed (instead of whether they overlap).
Code Co-occurrence Model (Code Occurrence) works like the earlier Code Co-occurrence Model, except that the occurrence of two codes in each of the selected documents is analyzed (instead of whether they overlap).
Code Distribution Model places the code at the center. The code is surrounded by all of the documents in which this code appears, linked with lines.
在线留言
尊敬的客户朋友,如您有任何意见建议,请通过下表反馈给我们,我们会尽快与您联系。
|