9.6版最新更新
版本9.6
|
从固定到灵活的试验设计,nQuery 9.6 是一项重大更新,可帮助生物统计学家和临床研究人员节省成本并降低风险。
亮点包括:
- 组序贯设计改进
- 二阶段II期设计(Simon设计)
- II期选择设计
- 多区域临床试验
- 疫苗研究
- 生物等效性
- 相关性
- 图表功能
|
|
nQuery 专业版
nQuery PRO 版有哪些新功能?
nQuery 9.6 专业版在以下方面添加了 7 项新的样本量表/功能:
- 组序贯设计改进(3个表格)
- 二阶段II期设计(Simon设计)(2个表格)
- II期选择设计(1个表格+更新)
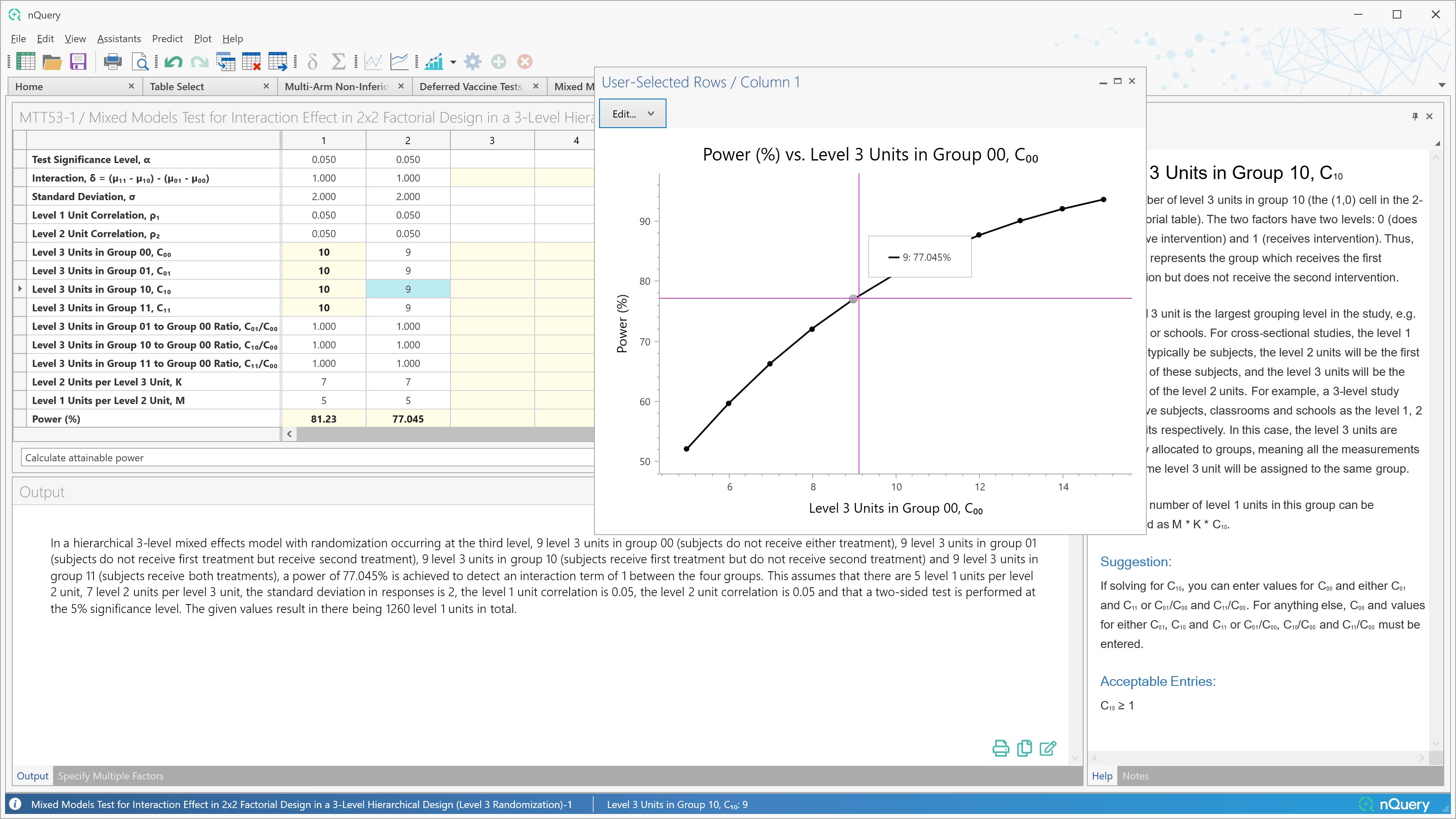
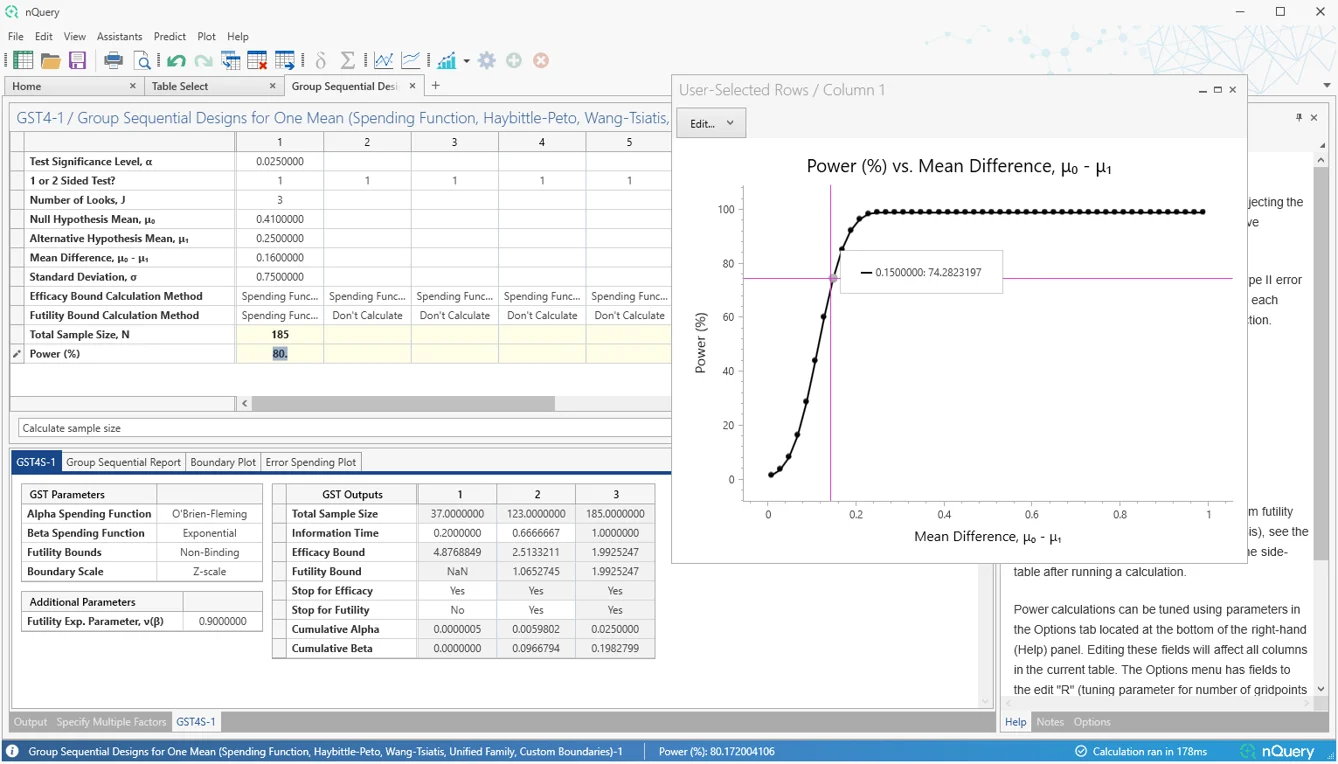
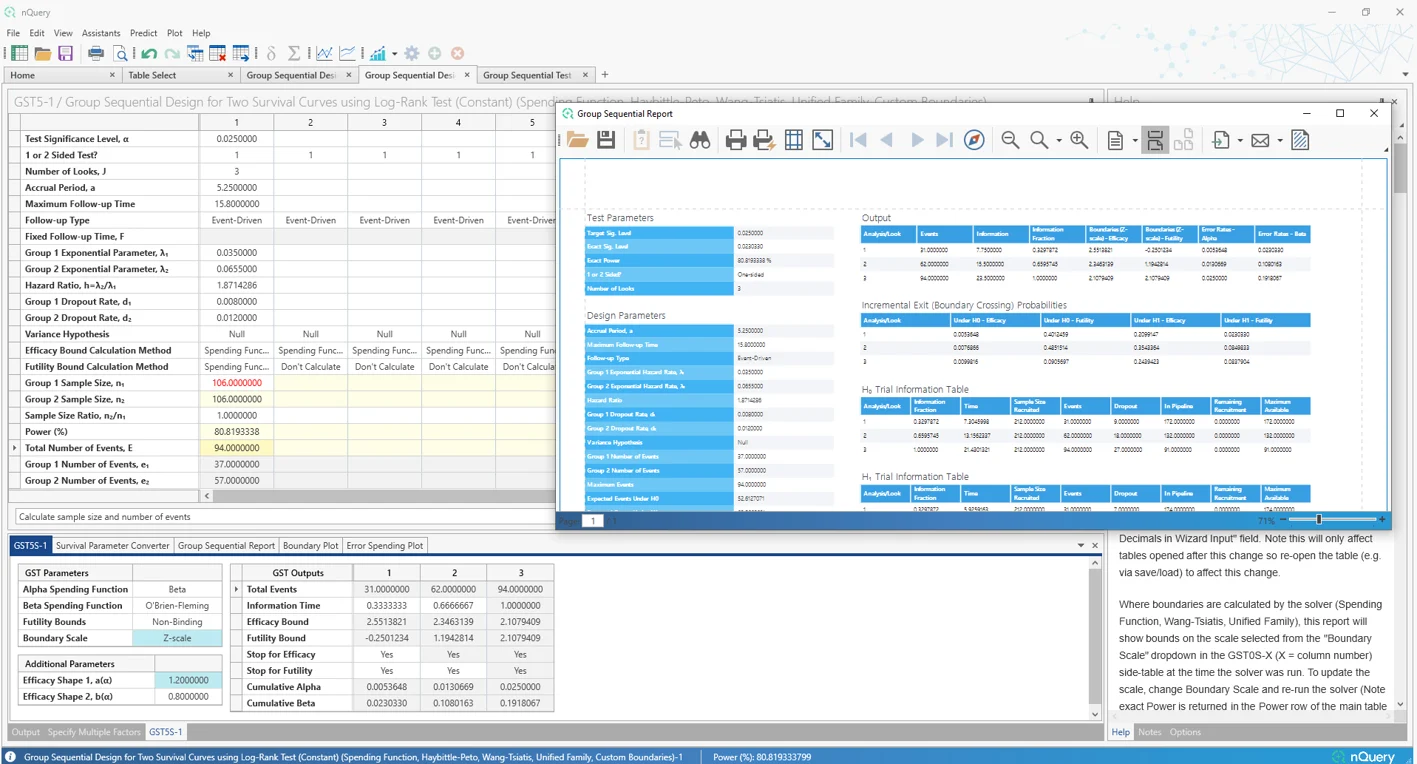
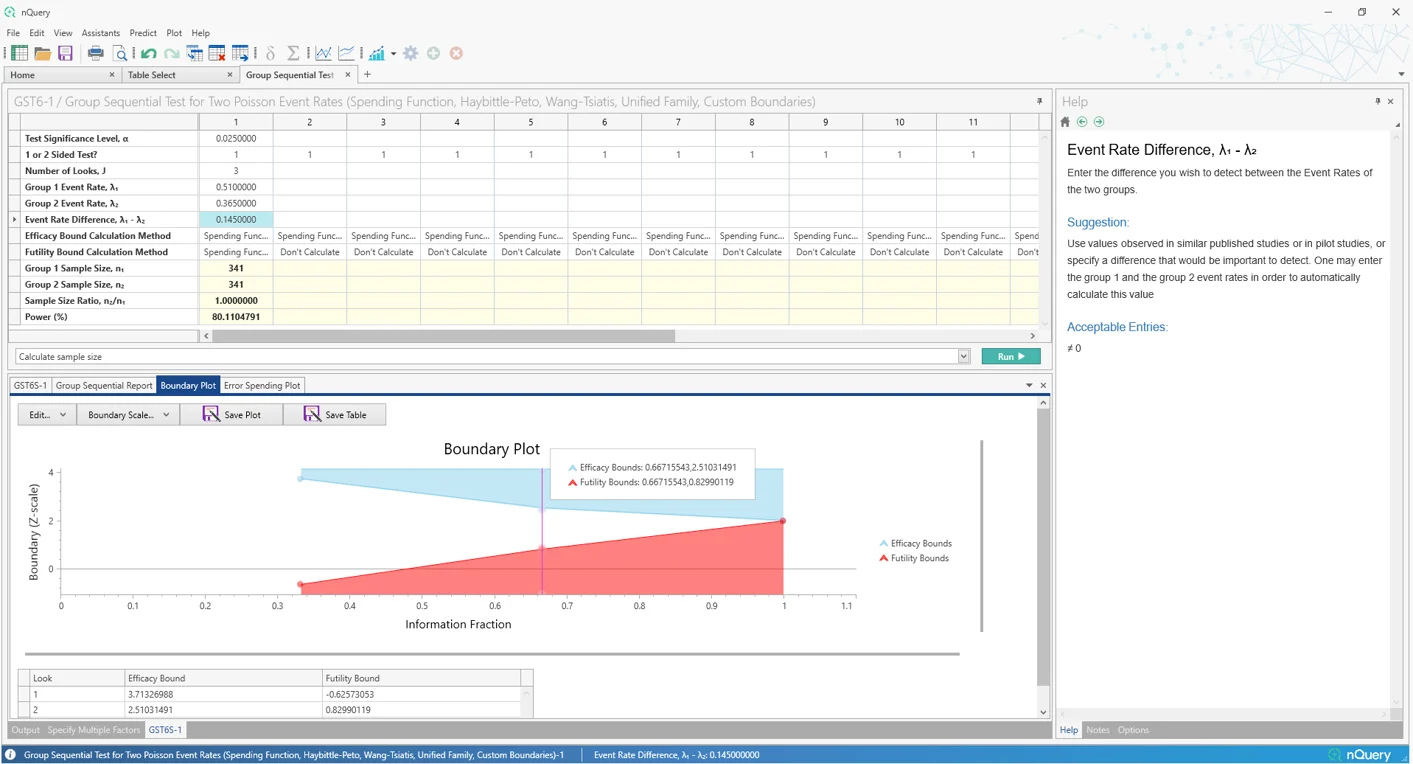
1. 组序贯设计改进
这是什么?
组序贯设计是验证性临床试验中最常用的自适应设计。这种设计允许试验者在预先指定的中期分析中,如果,有足够的证据表明治疗有效(有效性)或无效(徒劳),则可以提前停止试验。组序贯设计早期停止试验的能力可以显著节省成本,同时还可以更快地将重要治疗方法交到患者手中。Lan-DeMets 误差消耗函数等方法使试验者在保持试验监控期间显著灵活性的同时,可以灵活定义试验提前停止的条件。
改进的组序贯表格包括许多额外的组序贯方法、用户体验的重大改进,以及额外的详细输出,以更好地探索不同的组序贯场景。
nQuery 9.6 为单样本均值、双计数(泊松)和双样本对数秩检验(恒定入组率、风险比)场景添加了改进的组序贯表格。这些建立在自 nQuery 9.3 以来添加的改进组序贯表格之上。未来更新将扩展到更多场景。
新增改进的表格:
- 单均值的组序贯设计
- 对数秩检验的组序贯设计(恒定入组率、风险比)
- 双计数的组序贯设计(泊松)
组序贯设计改进摘要:
- 11 种消耗函数(O'Brien-Fleming、Pocock、Power Family、Hwang-Shih-DeCani、指数、贝塔、t 分布、逻辑、正态、柯西、用户定义/插值)
- Wang-Tsiatis 和 Pampallona-Tsiatis 设计
- Haybittle-Peto(p值)设计
- 统一家族设计
- 具有自定义 Z 统计量、p 值、评分统计量或效应量边界输入的自定义边界设计
- 双侧徒劳边界
- 新的用户响应界面
- 边界参数化转换
- 详细且可导出的组序贯报告
- 改进的可编辑边界图
- 误差消耗图
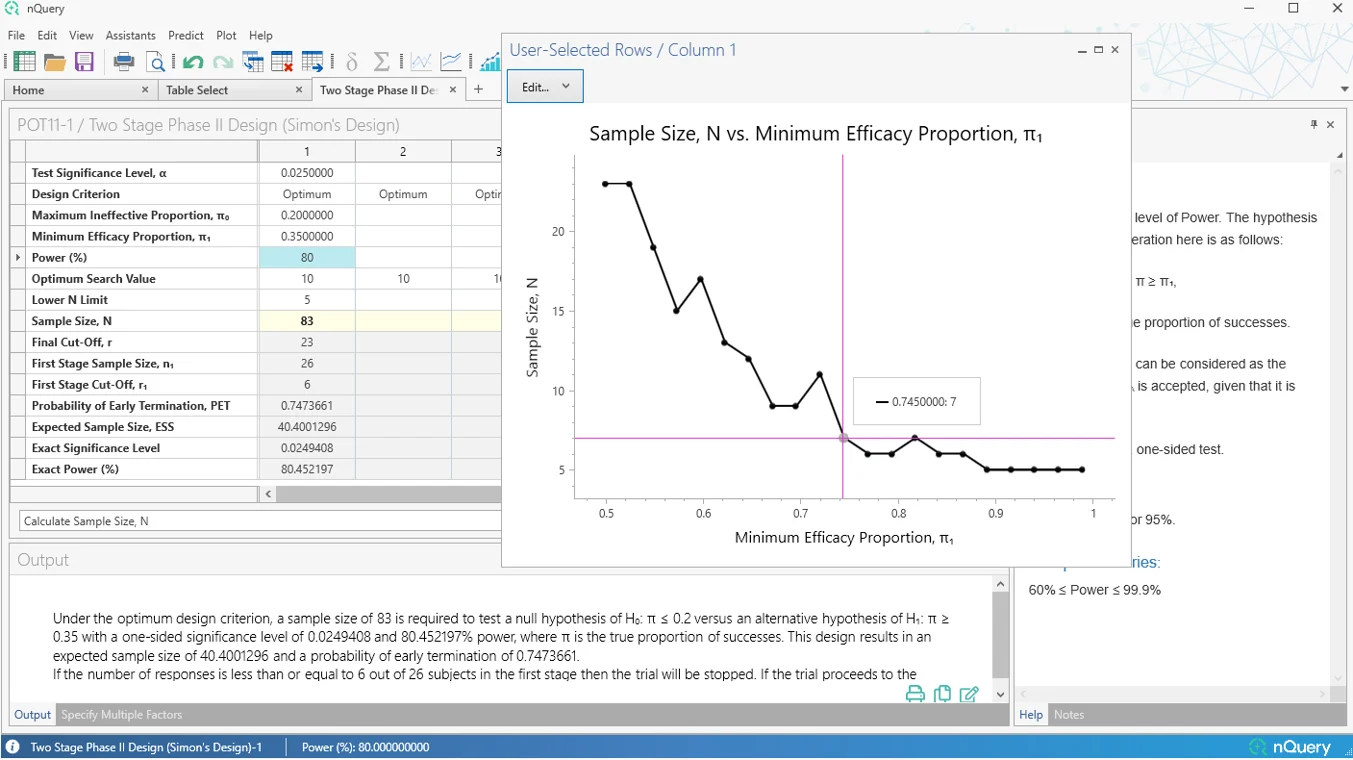
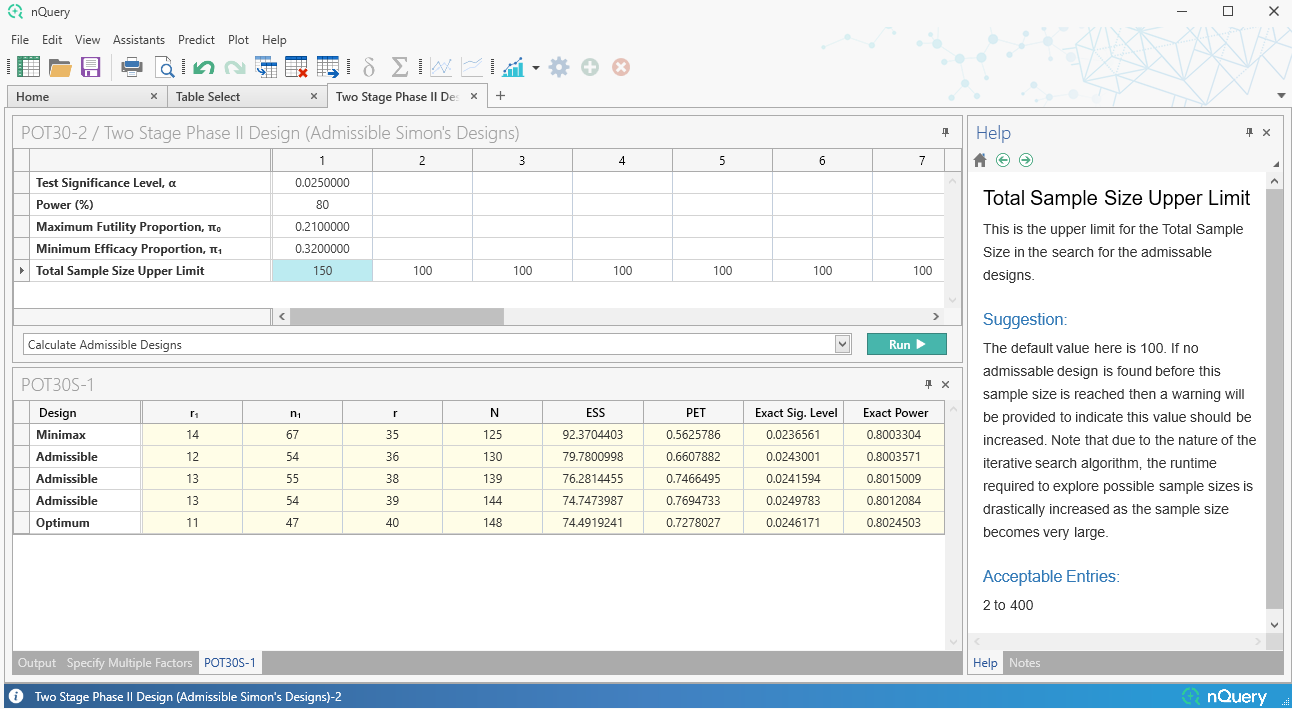
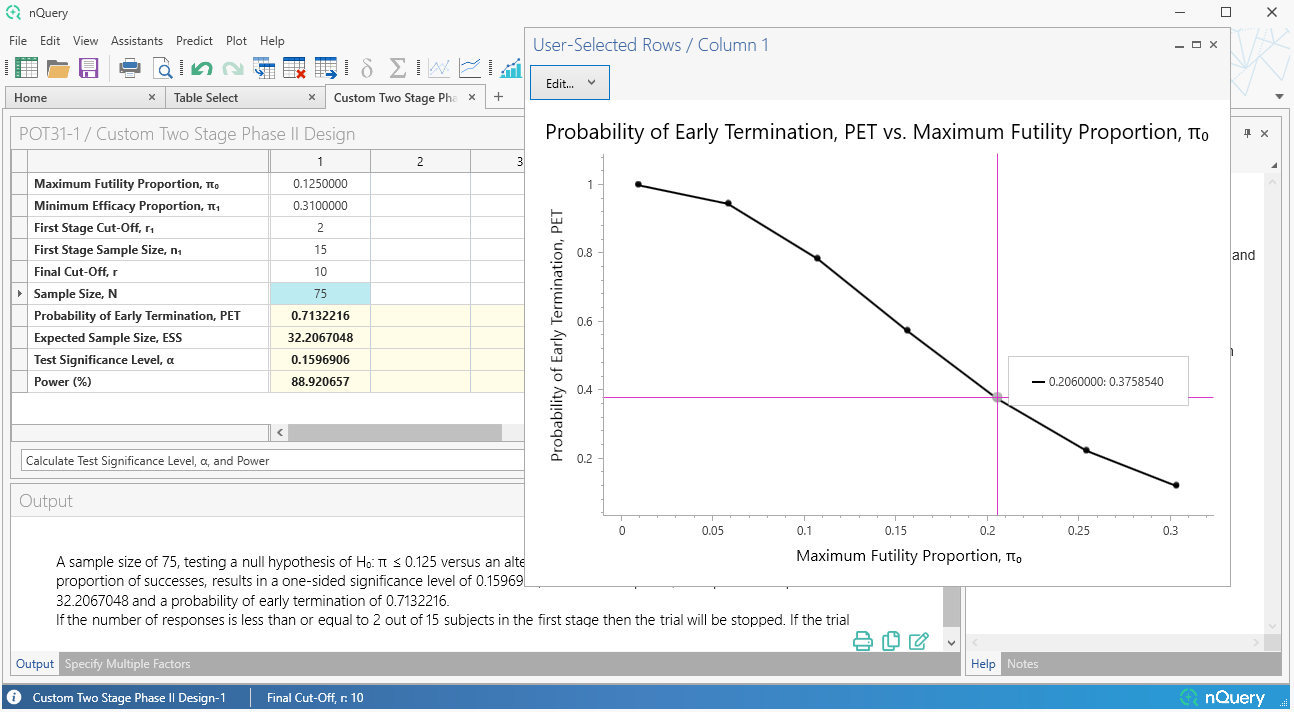
2. 二阶段II期设计(Simon设计)
这是什么?
早期II期设计常用于确定新的程序或治疗是否有可能达到基本的疗效水平,以 warrant 进一步开发或评估(概念验证)。二阶段设计是概念验证试验中常用的方法,因为它允许灵活地提前停止无效试验——因为II期是药物评估中最常见的失败点。
II期临床试验中最常用的二阶段设计之一是Simon二阶段设计。Simon二阶段设计是一种精确设计,在允许零假设和备择假设灵活性的同时,也允许提前停止...
nQuery 9.6 版本扩展了我们 nQuery 8.5 更新中的Simon设计产品,添加了更灵活的Simon类型设计选项。
首先,添加了一个表格,用于查找完整的"可接受"设计集合——这些设计在最大和预期样本量之间取得平衡,并提供超出最优设计和极小极大设计的更多潜在设计选项。
其次,添加了一个完全自定义的二阶段表格,允许指定任意的停止规则集,然后允许计算该设计的经验I类/II类误差。我们还在现有的Simon设计表格(POT11)中添加了"自定义"选项,允许用户找到总样本...
新增表格:
- 可接受的Simon设计
- 自定义二阶段(Simon)II期设计
表格改进:
- POT11:二阶段II期设计(Simon设计)- 添加了"自定义"设计标准
3. II期(Simon)选择设计
这是什么?
在竞争选项中选择正确的治疗或剂量是临床试验开发中的常见问题。各种设计和提案已被提出以帮助解决这一问题。Simon、Wittes和Ellenberg(1985)的一个早期提案是一种设计,将受试者随机分配到若干同等规模的组,然后选择获得最高反应率的组为获胜组。这通常被称为II期Simon随机化设计,是一种选择设计或"选赢者"设计。
他们的论文还推导出了给定设计选择最佳组的概率所需的精确计算。在 nQuery 9.6 中,此计算用于根据选择最佳组的目标概率推导II期Simon随机化设计的样本量确定。
新增表格:
如何更新?
如果您订阅了 nQuery Pro版,nQuery 应该会自动提示您更新。您可以通过单击 帮助>检查更新来手动更新 nQuery Advanced。
nQuery 基础版
nQuery 基础版有哪些新功能?
nQuery 9.6 基础版在以下方面添加了 13 项新的样本量表/更新:
- 多区域临床试验(4个表格)
- 疫苗(2个表格)
- 生物等效性(1个表格)
- 相关性(1个表格)
- X轴自定义值图表功能
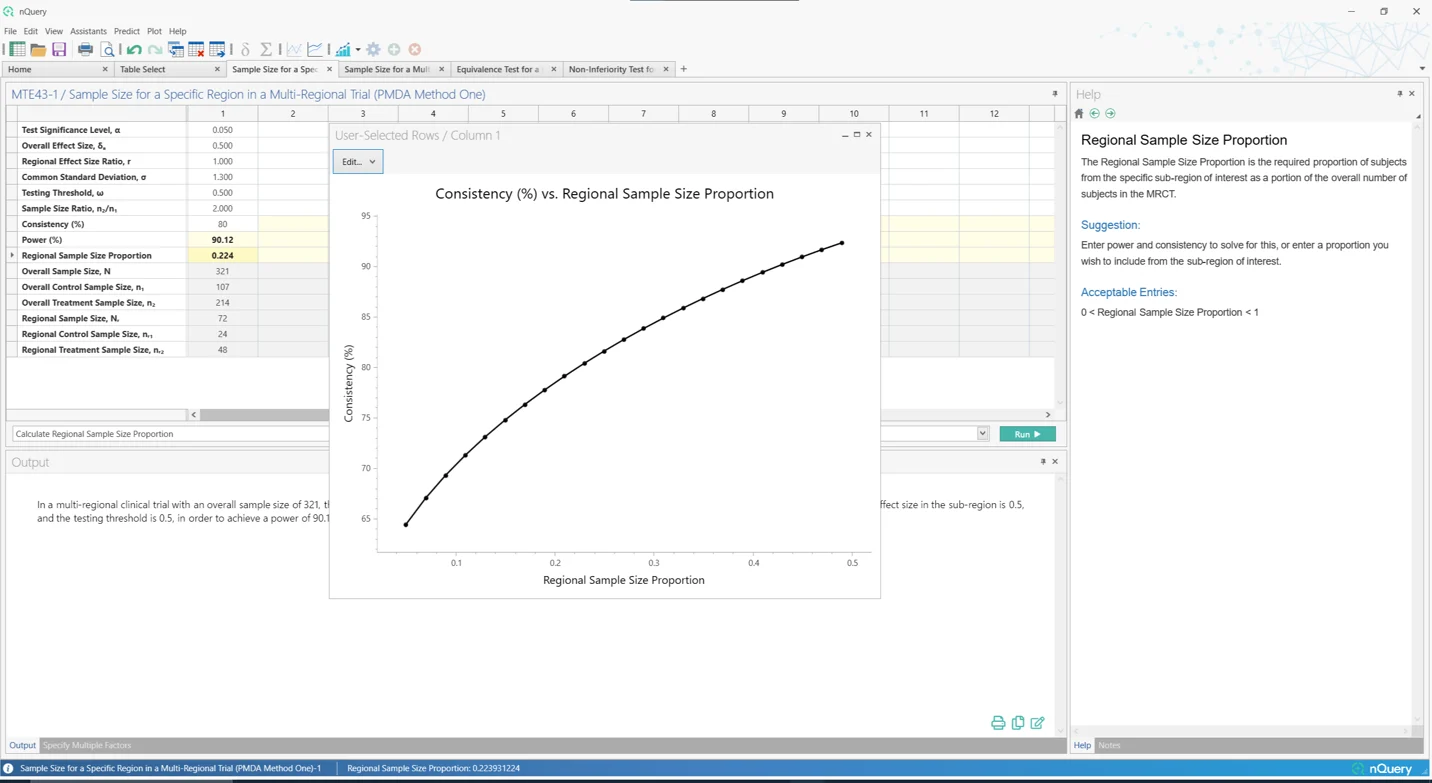
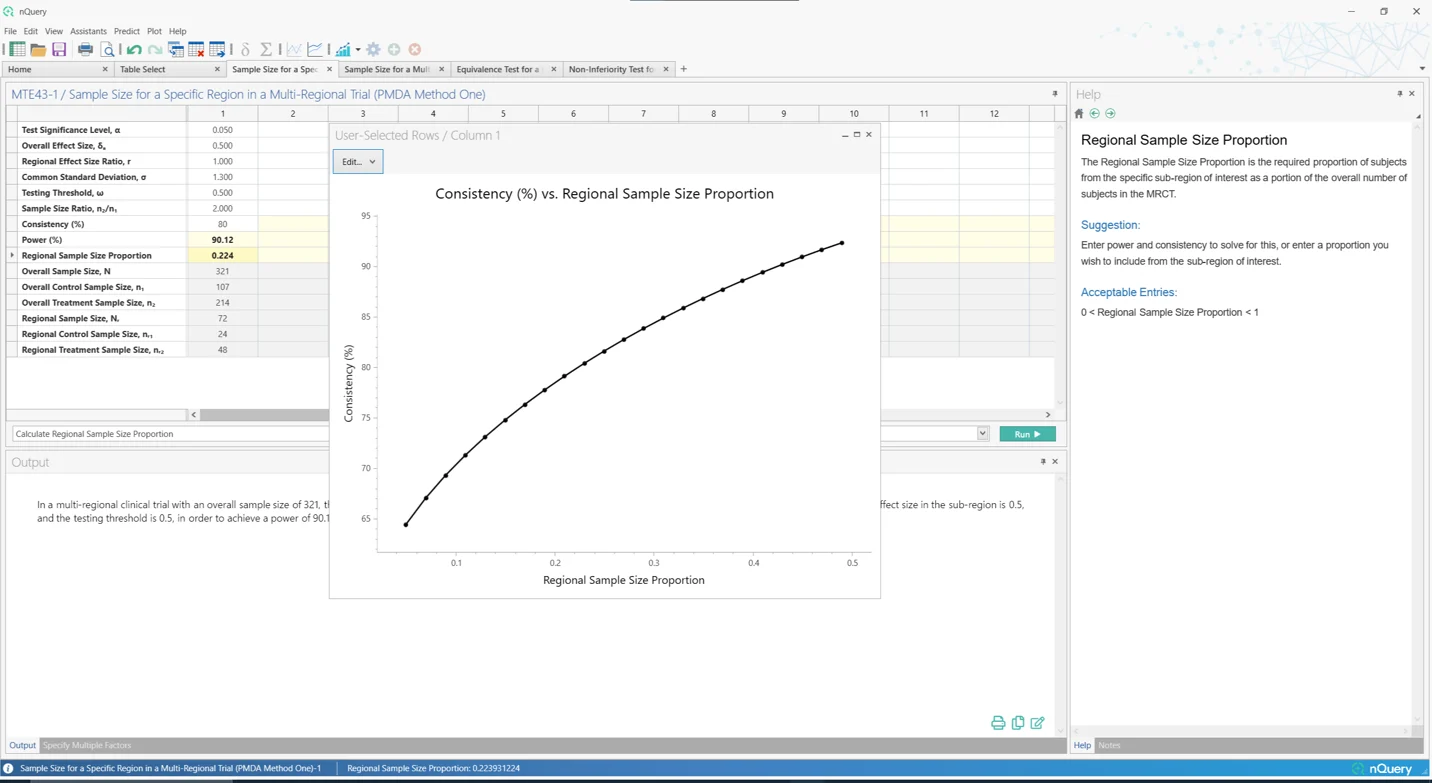
4. 多区域临床试验
这是什么?
多区域临床试验(MRCT)是在单一研究方案下在多个区域进行的试验。与传统方法(需要多项验证性试验以及特定辖区可能需要的额外桥接研究)相比,它们通过提供足够的证据用于基于单一高质量验证性临床试验在多个区域获得监管批准,因此可以显著节省时间和资金,因而使用量迅速增长。
由于其普及,MRCT 的监管指南有所增加。监管机构关注的一个问题是如何在各区域适当分配样本量,以便结果可推广到其感兴趣的区域。日本监管机构(PMDA)定义了两个样本量标准,以确定如果使用 MRCT 寻求批准,在日本区域所需的分配。这些随后被整合到...
在 nQuery 9.6 中,添加了基于多区域临床试验样本量分配的第一(局部显著性)和第二(效应保留)PMDA 标准样本量分配表格。此外,还添加了桥接研究方法的表格,当某地区需要额外试验才能获得批准时使用。
新增表格:
- 多区域试验中特定区域的样本量(PMDA方法一)
- 多区域试验的样本量(PMDA方法二)
- 桥接研究的两均值非劣效性检验
- 桥接研究的两均值等效性检验
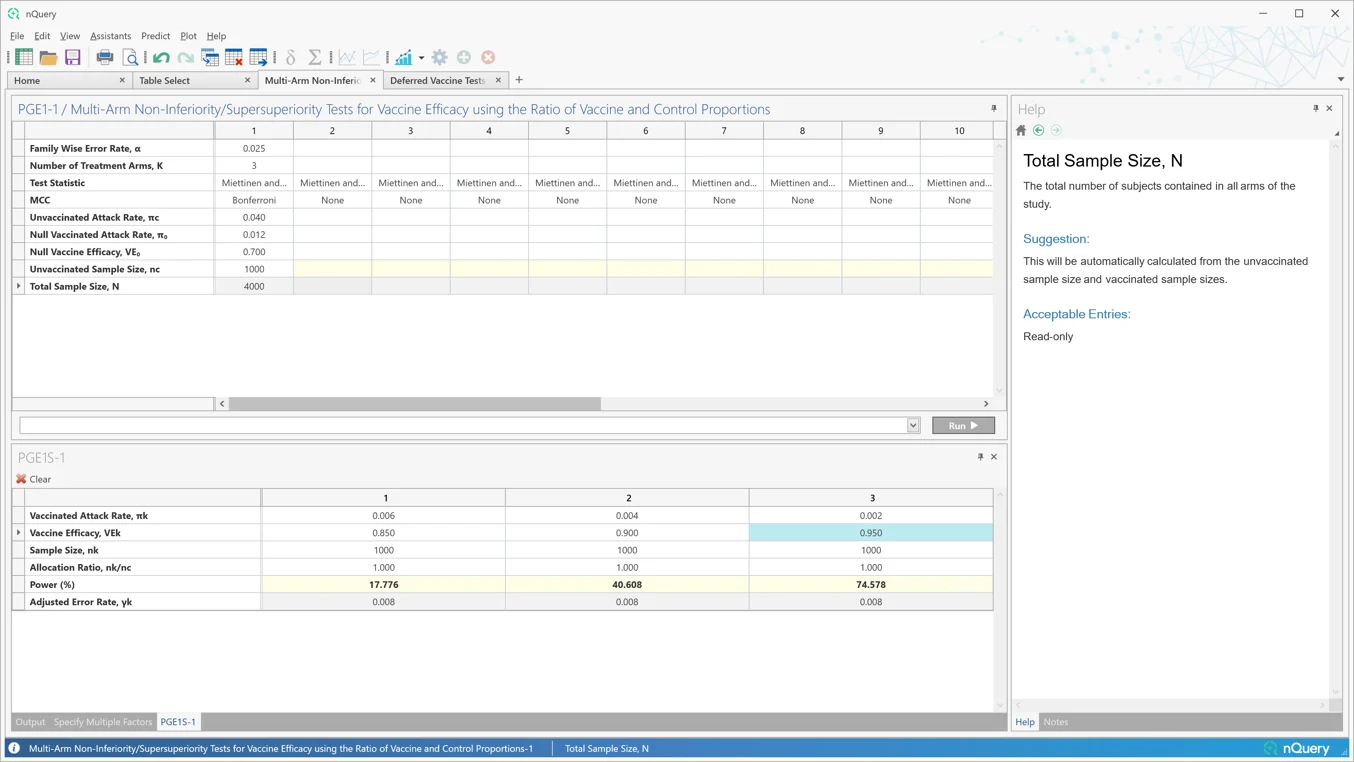
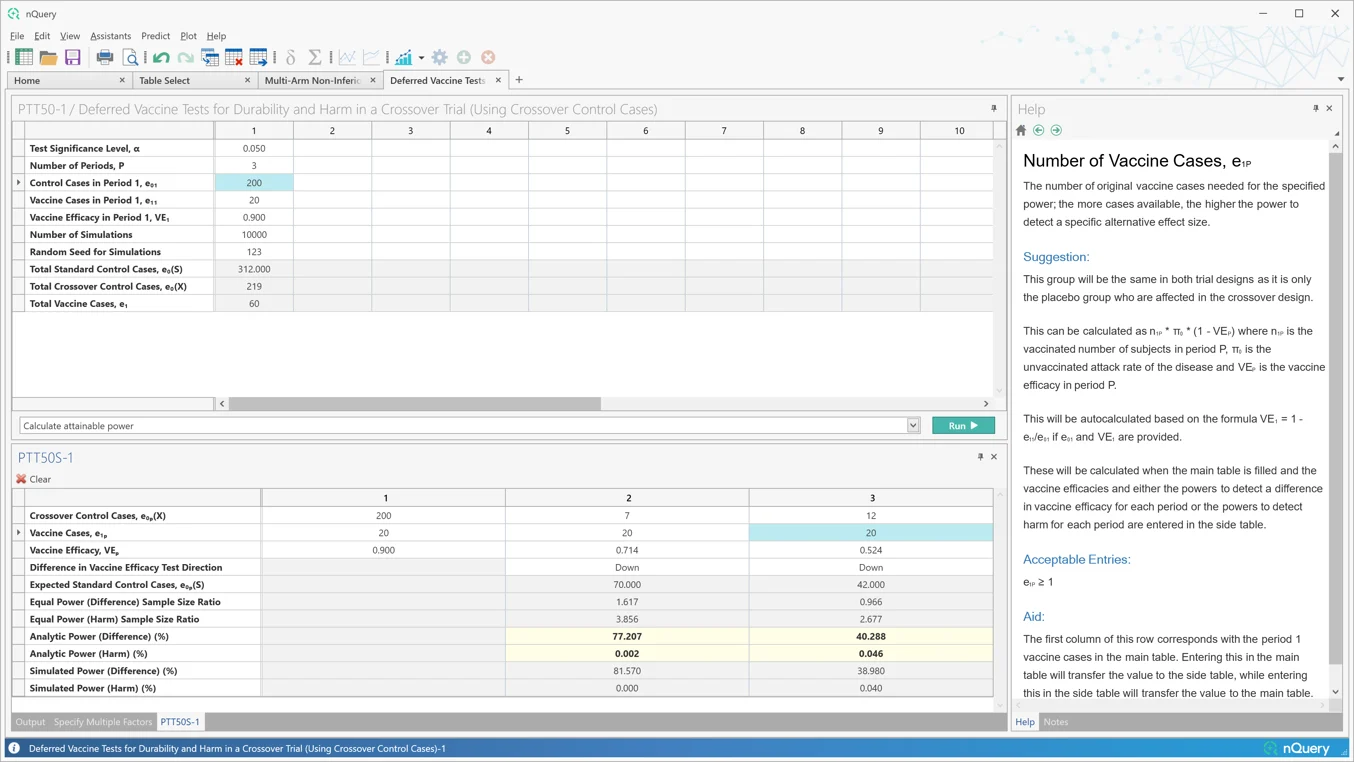
5. 疫苗研究
这是什么?
疫苗是临床历史上最成功的医学创新之一。然而,疫苗的独特性质——它们提供给整个人群,而不仅仅是患有目标疾病的患者——在设计临床试验时带来了独特的挑战。因此,样本量等试验设计考虑因素需要整合这些挑战,以确保最佳的试验结果。
疫苗效力是临床试验的主要目标,也是大多数新疫苗批准的基础。但是,人们对超越最常见的两臂平行设计的疫苗效力设计感兴趣。
然而,其他疫苗特征的试验可能也令人感兴趣,如疫苗安全性、疫苗持久性和疫苗加强针的影响。需要创新的设计方法来研究疫苗性能的这些方面。
nQuery 9.6 在 nQuery 9.5 添加的 8 个疫苗设计表格的基础上,添加了多臂场景中疫苗效力的表格,并将延迟疫苗危害/持久性计算扩展到交叉对照。
新增表格:
- 使用疫苗和对照比例比值的多臂非劣效/优效性检验疫苗效力
- 交叉试验中延迟疫苗持久性和危害的检验(使用交叉对照病例)
6. 生物等效性
这是什么?
生物等效性测试是批准新仿制药的最常见途径。该测试包括使用两种单侧检验(TOST)或等效置信区间方法评估药代动力学(PK)参数曲线下面积(AUC)和最大浓度(Cmax)是否相等。
交叉设计是按照预先指定的顺序对每个受试者进行多次治疗的设计。最常见的交叉设计是 2x2 设计,其中每个受试者接受治疗,一半先接受治疗,然后对照,另一半先接受对照,然后进行治疗。
然而,还有许多高阶交叉设计也常被使用,当存在多种治疗/剂量、高度可变...
新增表格:
- 交叉设计等效性检验(原标度)差异(2x2x2、2x2x3、2x3x3(部分重复)、2x2x4、2x4x2(Balaam's)、2x4x4、3x3x3、3x6x3、4x4x4、2x2x2r(Liu))
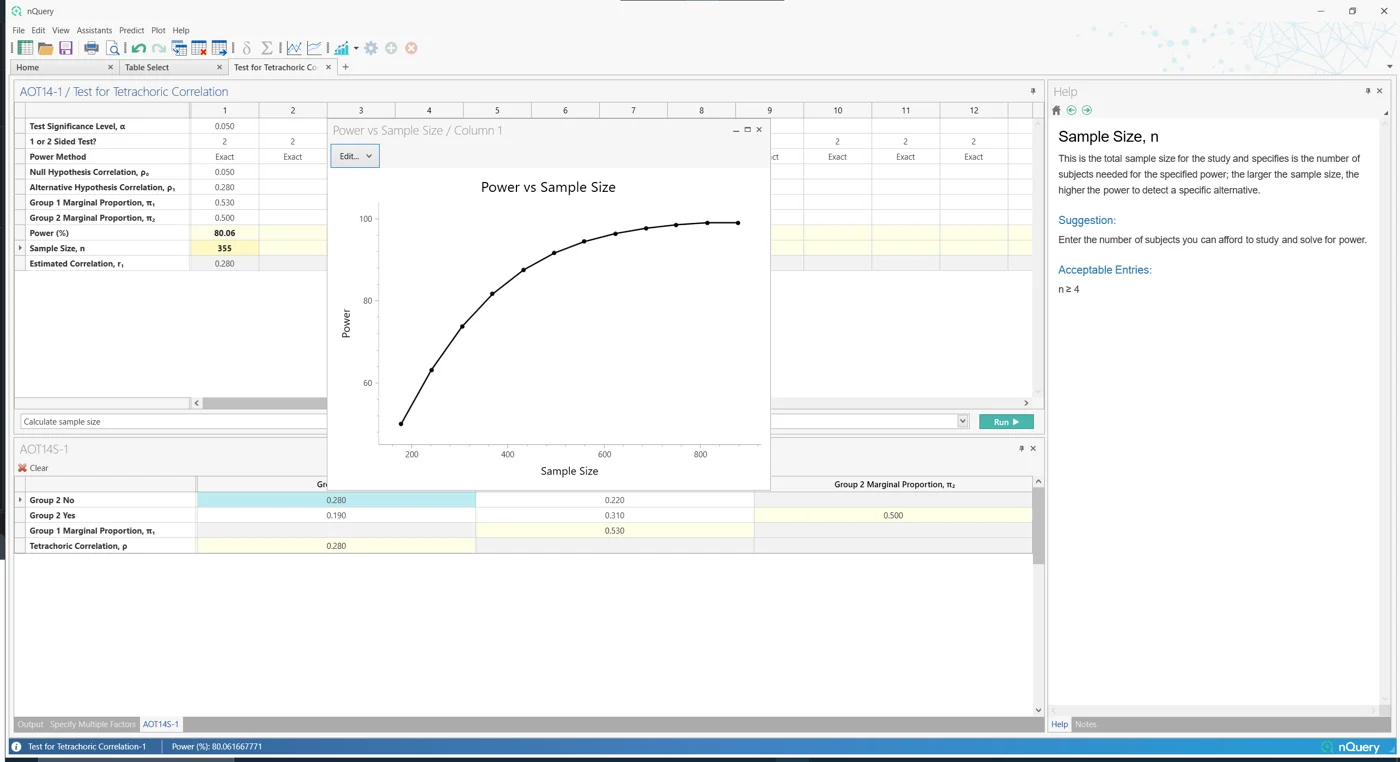
7. 相关性
这是什么?
相关性度量有兴趣评估两个变量之间关系的强度。常见的相关性度量包括Pearson、Spearman和Kendall-Rank。
依赖性相关表明存在一个共同因素,可能导致两个相关性之间的关系,这等同于指出至少有一个配对相关系数不为零。当两个相关性有一个共同的测量指标(这里称为"y")时,通过比较,其他两个测量指标与共同测量指标的相关性必然是依赖性的。
在 nQuery 9.6 中,添加了四分相关表,可用于评估使用二分数据测量的两个连续变量之间的关系。
新增表格:
8. 图表功能
这是什么?
图表用户选择行功能提供了一种易于使用且强大的方式,可以在我们的设计表格中评估给定输入行与给定求解行之间的关系。
到目前为止,输入行绘制的值仅限于指定最小值、最大值和步长,以自动生成绘制值的集合。
在 nQuery 9.6 中,"X轴自定义值"按钮将允许用户完全指定所需的输入行值,并为用户提供更多能力来生成他们感兴趣的具体图表。
如何更新?
如果您订阅了 nQuery 基础版或 nQuery Plus 版,nQuery 应该会自动提示您更新。您可以通过单击 帮助>检查更新来手动更新 nQuery Advanced。
在线留言
尊敬的客户朋友,如您有任何意见建议,请通过下表反馈给我们,我们会尽快与您联系。
|

 Selection Design.png)