|
MLwiN 2.36-多层模型拟合软件包|MCMC estimation 特征
MLwiN和多层建模 Multilevel modelling has rapidly become established as the appropriate tool for modelling data with complex hierarchical structures. It is important for extending our understanding of social, biological and other sciences beyond that which can be obtained through single level modelling. Multilevel modelling is now being used in Education, Medical science, Demography, Economics, Agriculture and many other areas. The term multilevel refers to a nested membership relation among units in a system. In an education system, for example, students are members of classes, and classes are grouped within schools. When 'single level' techniques such as multiple regression are applied to data from a structure such as this, the analysis will ignore important aspects of the data structure and the results will often be misleading. Multivariate regression and multivariate analysis of variance can be conducted in a particularly flexible manner using a multilevel approach. The models can also be used to fit growth curves and other repeated measures data with either continuous or discrete responses, estimate variance and covariance components from studies with complex designs, and analyse data from studies employing rotation sampling. Multilevel time series data can be modelled. Multilevel generalised linear models can be fitted: for example, logit, log-log or probit models for binary response data and macros are available for multinomial ordered or unordered logistic models. Multilevel survival or event history models can be fitted. Complex sample survey data can be modelled flexibly and efficiently. MLwiN图形界面 An important feature of MLwiN is its graphical interfaces. These allow the user easily to set up, fit and manipulate models. There are windows for data manipulation, plotting, viewing the progress of iterations etc. Predictions from fitted models can be specified directly using standard statistical notation with direct links to various kinds of derived graphs, which are automatically updated as model parameters change. Likewise, posterior residual estimates and functions of them can be linked directly to graphs, for example for model diagnostics. Multivariate models are simple to specify using a special input screen. Complex variance functions can be specified and the software will allow linear and non-linear modelling of variances as functions of explanatory variables with an interactive screen, which displays the resulting model in standard notation. Markov Chain Monte Carlo (MCMC) Bayesian modelling is incorporated with detailed visual diagnostics. Parametric nd non-parametric bootstrapping is available and an iterated bootstrap has been implemented for unbiased estimation with multilevel generalised linear models. Graphing in MLwiN Extensive plotting facilities are available. Any graph can be altered in terms of colour, symbols, lines etc. We can superimpose graphs, lay them out in patterns (such as trellis plots), label them, identify points or lines on them in terms of data units and copy and paste them to other applications. Several special kinds of graphs are created directly by the software, for example for displaying diagnostics. The caterpillar graph below is created from the residuals window and represents a set of ordered shrunken residual estimates of school effects with 95% confidence intervals from a variance components model.
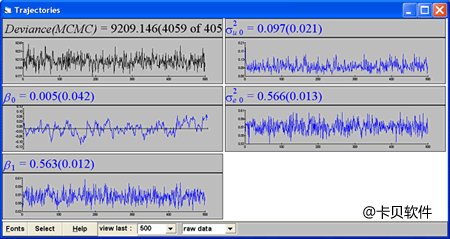
MCMC estimation in MLwiN Markov Chain Monte Carlo (MCMC) methods allow Bayesian models to be fitted, where prior distributions for the model parameters are specified. By default MLwiN sets diffuse priors which can be used to approximate maximum likelihood estimation. Two procedures are used by MLwiN. Gibbs sampling is used with Normal responses and the Metropolis-Hastings algorithm with Normal or binary/proportion responses - these are the only ones available in release 1.0. Estimation is controlled using options that appear on the toolbar when MCMC is selected or the estimation control button is pressed. The following items can be controlled. Burn in This is the number of initial iterations which will not be used to describe the final parameter distributions; that is they are discarded to allow Markov chain to converge to the posterior distribution. Monitoring After the burn in period, the monitoring period is the number of iterations, after which distributional summaries are to be produced. Refresh This specifies how frequently the parameter estimates are refreshed on the screen during iterations. Thinning This is the frequency with which successive parameter values in the Markov chain are stored. For Metropolis-Hastings there are some additional parameters to be set. While iterations are taking place you can view their progress in a trajectories window such as the following for a random coefficient Normal model:
Monitoring MCMC estimation MCMC methods allow Bayesian models to be fitted with prior parameter distributions. By default MLwiN sets diffuse priors. Both Gibbs sampling and Metropolis Hastings sampling can be used. We can obtain summary measures and diagnostics by clicking on any of these graphs - and obtain a window such as the following which shows a kernel density plot, autocorrelation functions and estimates of required chain length etc. for the level 1 variance parameter: If an informative prior had been specified the distribution would be superimposed on the posterior kernel density.
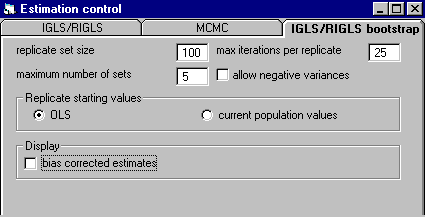
Bootstrapping in MLwiN MLwiN has powerful facilities for carrying out parametric bootstraps for any of the models fitted. This allows for exact inferences and also for bias correction - which is particularly important when using quasi-likelihood estimation for generalised linear multilevel models where an iterative bias correction is required. The bootstrap control menu is as follows:
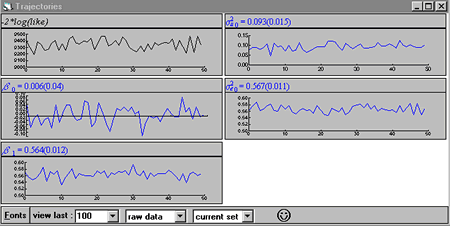
There are options for specifying the number of replicates (if an iterative bootstrap is required) replicate set size, starting values and whether bias correction of estimates is required. Using the trajectories window, the progress of iterations can be monitored, as below.
Along the bottom toolbar you can set the number of most recent parameter set estimates, whether you wish to view each parameter estimate as it is calculated or the running means, and whether, for an iterated bootstrap, you wish to observe the progress for the current replicate set or just plot the series of bias corrected estimates: the latter is recommended in order to view convergence, but you may switch between views by selecting this dialogue box. At the end, or at any other time, you may view the summary bootstrap estimates simply by clicking on the plot for the parameter you are interested in. If you click in a trajectories window you will be presented with a kernel density plot, a summary set of quantiles, the mean and standard error computed from the bootstrap replicates. If you specified scaling on the bootstrap menu then all these will be scaled. 系统需求 MLwiN 2.10(和后续版本)能够安装到下列操作系统中:
|
|
|
| 站点地图|隐私政策|加入我们 |
©2022 上海卡贝信息技术有限公司 All rights reserved. |